mAP trong object detection
Xin chào ae hôm nay tôi sẽ trình bày một metric rất phổ biến trong object detection là mAP.

1. Giới thiệu qua
Như ae đã biết thì khi chúng ta huấn luyện một model deeplearning thì một việc chúng ta phải làm đó là đánh giá hiệu suất của model. Nếu như trong bài toán classification thì ta có thể đơn giản dùng precision để đánh giá model bằng cách lấy tổng số sample được phân loại đúng trên tổng số sample thực hiện phân loại, hay có thể sử dụng F1 score để tính,… thì trong object detection để đánh giá hiệu suất của model thì người ta sử dụng mAP như là một metric phổ biến để đánh giá hiệu suất của model. Trước khi đến với phần giải thích thì mình xin lưu ý là cùng là mAP trong object detection nhưng lại có những cách tính khác nhau. Bài viết này mình xin trình bày cách tính mAP theo coco dataset nhé, đây là cách tính mAP mình thấy rất phổ biến. Một cách tính khác các bạn có thể tham khảo theo link sau (thực ra nó cũng na ná nhau). Oke lét sờ gâu ….
2. Tổng quan về precision và recall
Trước khi đi vào tính phần mAP thì chúng ta sẽ phải hiểu được một số khái niệm là precision và recall, thực ra là 2 khái niệm này thì đã rất quen thuộc trong bài toán classification. Đầu tiên ta sẽ nhắc lại một số khái niệm cần thiết về precision và recall trong bài toán classification. Để dễ minh họa ta sẽ lấy một ví dụ là thực hiện bài toán phân loại mèo và không phải là mèo. Thì khi đó nếu model nhận diện một bức ảnh là mèo thì nó sễ được coi là positive và ngược lại nó sẽ là negative. Còn True và False sẽ đại diện cho việc nhận diện đúng hoặc sai của model so với nhãn thực (label) :
- TP (True positive): Model nhận diện nó là mèo và đúng thật bức ảnh đó là mèo.
- FP (False positive): Model nhận diện nó là con mèo nhưng nhãn thực tế (label) không phải là con mèo (có thể là con chó…)
- TN (True negative): Model nhận diện nó không phải là con mèo và đúng thật là bức ảnh đó không phải là con mèo (oto, xe máy, tokuda,..)
- FN (False negative): Model nhận diện nó không phải là con mèo nhưng thực tế nó con mèo.


Cách đánh giá như trên
thường áp dụng vào bài toán phân loại 2 lớp trong đó có một lớp quan trọng cần
quan tâm ví dụ như phân loại một bức ảnh có phải là chó hay không và ta quan
tâm đến việc model phân loại là chó. Còn đối với bài toán nhiều lớp thì ta cũng
có thể quy nó về 2 lớp bằng cách xét lần lượt từng lớp là đối tượng mà ta quan
tâm (positive) và tất cả các lớp còn lại negative hay một cách biểu diễn khác
chính là . Và 2 công thức precision và recall phía trên ta có thể dễ dàng suy
ra được precision nó đại diện cho độ chính xác khi dự đoán của model vì nó bằng
số phân loại đúng (những đối tượng mà ta quan tâm ) trên tổng số phân loại (bao
gồm cả những đối tượng mà ta không quan tâm). Còn recall nó chính là độ phủ nó
thể hiện được việc model đã phân loại được bao nhiêu đối tượng positive trong số
những đối tượng positive đã có. Về mặt lý thuyết thì precision và recall cùng bằng
1 thì model nó là bố của ngon rồi nhưng thực tế sẽ có một sự đánh đổi nhất định
nào đó và ta sẽ thấy rõ điều đó khi ta vẽ đường cong precision và recall.
3. Precision và recall trong object detection
Bên trên là mình nhắc lại một số khái niệm cơ bản về precision vs recall trong classification. Trong object detection thì cách tính precision vs recall cũng tương tự như vậy nhưng cách định nghĩa TP, TN, FP, FN có sự khác biệt, nó sẽ xử dụng một thông số khác là IOU (intersection over union) nó đơn giản là tỉ số của diện tích trùng lặp của 2 bouding box trên diện tích hợp của 2 bouding box.

Dựa vào thông số IOU này người ta sẽ xác định TP, FP, TN, FN như sau:
- TP
(True positive): Khi IOU của predicted box vs gtbox
iou threshold
- FP (False positive): Khi IOU của predicted box vs gtbox < iou threshold
- TN (True negative): Thông số này ta có thể hiểu nó như là background và ta sẽ không cần quan tâm thông số này.
- FN (False negative): Bouding box của đối tượng không được detect (detect sót)
Và sau đó precision và
recall vẫn được tính theo công thức trên:

Từ công thức precision
ta có thể suy luận ra nó chính là độ chính xác của model khi model detect được
một đối tượng nào đó. Ví dụ precision = 0.9 thì có nghĩa là khi model detect được
một đối tượng nào đó thì độ chính xác của nó lên tới 90%.

Từ công thức tính recall ta có thể suy luận ra nó chính là khả năng model detect được tất cả các đối tượng có liên quan. Ví dụ recall = 0.7 thì trong số 10 đối tượng trong bức ảnh thì model có khả năng detect đk 7 thằng trong đó.
4. Average precision
Từ precision và recall đã tìm được ở phía trên ta có thể vẽ được đường cong precsion theo recall (PR curve) cho mỗi class riêng biệt. Nó chỉ ra sự đánh đổi giữa precision và recall đối với nhiều giá trị confidence score khác nhau. AP( average precision) chính là phần diện tích phía dưới đường cong PR curve đã nói bên trên. Nếu phần diện tích này lớn đồng nghĩa với việc precision và recall sẽ cao đồng nghĩa model có chất lượng tốt. Và các bạn để ý là bên trên khi mình tính các giá trị TP, FP ta có sử dụng một thông số là threshold (tùy thuộc vào tập dataset mà ta đánh giá) nên AP có thể được kí hiệu là AP@α với α là giá trị threshold.
Để tính được AP thì ta
có 2 cách tính là 11-point interpolation và interpolation all point.
4.1 11-point interpolation
Đối với cách tính này ta sẽ chia recall từ 0 – 1 thành 11 đoạn cách đều nhau [0, 0.1, 0.2, .. 1] và lấy trung bình precision ở 11 điểm này.

Trong đó ρ(

4.2 Interpolation all point
Đối với cách tính này thì
thay vì chỉ nội suy 11 điểm cố định như đã chia ta sẽ nội suy tất cả n điểm mà
ta có theo công thức sau:
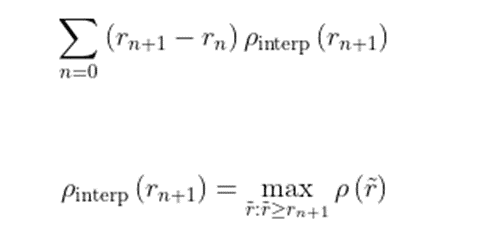
Trong đó ρ(
5. Ví dụ minh họa.
Nhìn lý thuyết về AP bên trên đôi khi sẽ khó hiểu nên mình sẽ lấy một ví dụ như sau:

Chúng ta có 7 bức ảnh và
giả sử chúng ta chỉ đang xét với 1 class và các hộp màu xanh lá cây tương ứng với
gtbox còn hộp màu đỏ tương ứng với predict box của model. Các giá trị % bên cạnh
các hộp màu đỏ ứng với confident score của model.
Đầu tiên ta sẽ tính TP
và FP như lý thuyết đã nói ở bên trên với ngưỡng iou là 0.3 có nghĩa nếu gtbox
và predict box có iou ≥ 0.3 thì sẽ được coi là TP còn không sẽ là FP.
Chú ý có thể đối với một gt box có nhiều predict box trùng lặp ví dụ như ở hình
số 2 ta thấy predict box D và E đều trùng lặp với cùng 1 gtbox thì khi đó predict
box nào có confident score cao hơn thì sẽ là TP còn thằng còn lại sẽ là FP, như
trong hình thì D là TP còn F là FP. Từ đó ta sẽ lập được bảng sau:

Từ bảng trên ta sẽ thực hiện 2 việc:
- Đầu tiên ta sẽ sắp xếp lại các predict box theo thứ tự giảm dần của confidents score.
- Ta sẽ tính giá trị accTP và accFP là các giá trị tích lũy của TP và FP như bảng sau

Chú ý khi này thì
precision và recall vẫn được tính như công thức đã nói phía trên nhưng thay TP,
FP thành AccTP, AccFP tương ứng. Và một điểm cần chú ý là trong công thức
recall thì mẫu số là TP + FN thì nó chính là tổng số gtbox nên mình ko cần quan
tâm tới FN nữa mà hiển nhiên tổng của nó = 15 rồi nhé.
Và ta sẽ có một PR-curve
như sau:

Như mình có thể thấy là
precision có xu hướng giảm xuống khi ta tăng recall tất nhiên là nó không giảm
đơn điệu nhưng nói chung là có xu hướng giảm.
Bây giờ ta sẽ tính AP từ đường cong RP-curve này theo lý thuyết bên trên. Ta sẽ thực hiện tính theo 2 cách là 11-point interpolation và interpolation all point
1. 11 - point interpolation

Đúng như lý thuyết đã
nói bên trên ta sẽ chia recall trong đoạn từ 0 – 1 thành 11 đoạn nhỏ tương ứng
với các vị trí chấm đỏ dóng xuống trục recall như trên hình và áp dụng đúng
công thức đã nói phía trên ta sẽ có kết quả sau:


2. Interpolation all point
Đối với cách tính này
ta cũng áp dụng đúng như công thức đã nói phía trên ta sẽ được như sau.

Để tính AP thì ta xấp xỉ
hình trên thành các hình chữ nhật như sau

Theo như công thức phía
trên thì AP chính là tổng diện tích của các hình chữ nhật: AP = A1+A2+A3+A4

Nhận xét ta thấy với 2
cách tính thì AP có một chút khác biệt tùy thuộc vào yêu cầu đánh giá đã được đề
ra của bộ dataset ví dụ như bộ dataset pascal voc hay MS Coco. Theo mình thấy
thì tính mAP theo cách 2 có vẻ phổ biến hơn.
6. mAP.
Sau khi tính được AP rồi thì bước cuối cùng là ta sẽ tính mAP. Vì bên trên là mình tính AP cho lần lượt từng class một nên mAP sẽ là trung bình cộng AP của tất cả các class.
Chú ý: Đôi khi các bạn có thể
bắt gặp kí hiệu mAP@[0.5:0.05:0.95]
thì các bạn có thể hiều giá trị mAP cuối cùng sẽ là trung bình cộng của các mAP
tương ứng với các IOU threshold (0.5, 0.55, .. 0.95) với step là 0.05.
7. Tóm tắt lại.
Nói chung mAP là một metric tương đối khó hiểu trong deeplearning vì thế mình viết tóm lại các bước ở đây để tóm gọn lại các bước để tính mAP còn chi tiết thì mình đã viết bên trên rồi.
Để tính
mAP chúng ta sẽ có các bước sau:
B1: Tính AP cho từng
class riêng biệt như đã trình bày bên trên
B2: Tính mAP bằng cách
lấy trung bình cộng của AP
B3: Tính trung bình của mAP theo các ngưỡng threshold (nếu bộ data yêu cầu)
Reference:
https://github.com/rafaelpadilla/Object-Detection-Metrics
Cảm ơn các bạn đã đọc bài viết, nếu thấy hay cho xin một like nhé...
d

Nhận xét
Đăng nhận xét